
By Dr. Robert Buccigrossi, TCG CTO
There is a strong push by the administration for Federal agencies to adopt artificial intelligence. But how can we support this shift when AI systems are opaque and unreliable?
One key is “Agentic AI”. These systems are designed to plan multi-step tasks, use tools, and make independent decisions. Yet for Federal systems, we cannot simply accept a vendor’s claim that their AI is accurate (including systems we develop ourselves). We need empirical evidence.
This past week (on April 7th), a webinar by the NIST Information Technology Laboratory (ITL) detailed an approach for AI systems to address this traceability gap. By deploying agentic “judges” that test for accuracy and generate rigorous machine-readable audit trails, NIST provided a pragmatic case study for establishing the visibility and trust required for federal AI deployments.
Deconstructing the “Deep Research” Testbed
To demonstrate these concepts, ITL developed an open-source “Deep Research” clone (released open source on Github). The harness was explicitly designed to allow engineers to inject measurement toolkits directly into the AI’s internal reasoning loops.
ITL’s Deep Research workflow uses a fixed, human-curated corpus of documents (as opposed to open internet searches). This approach improves retrieval quality and establishes an absolute ground truth. A claim generated by the AI is either explicitly supported by the provided text, or it is an error.
The workflow relies on fundamental constructs, using the following specialized agents:
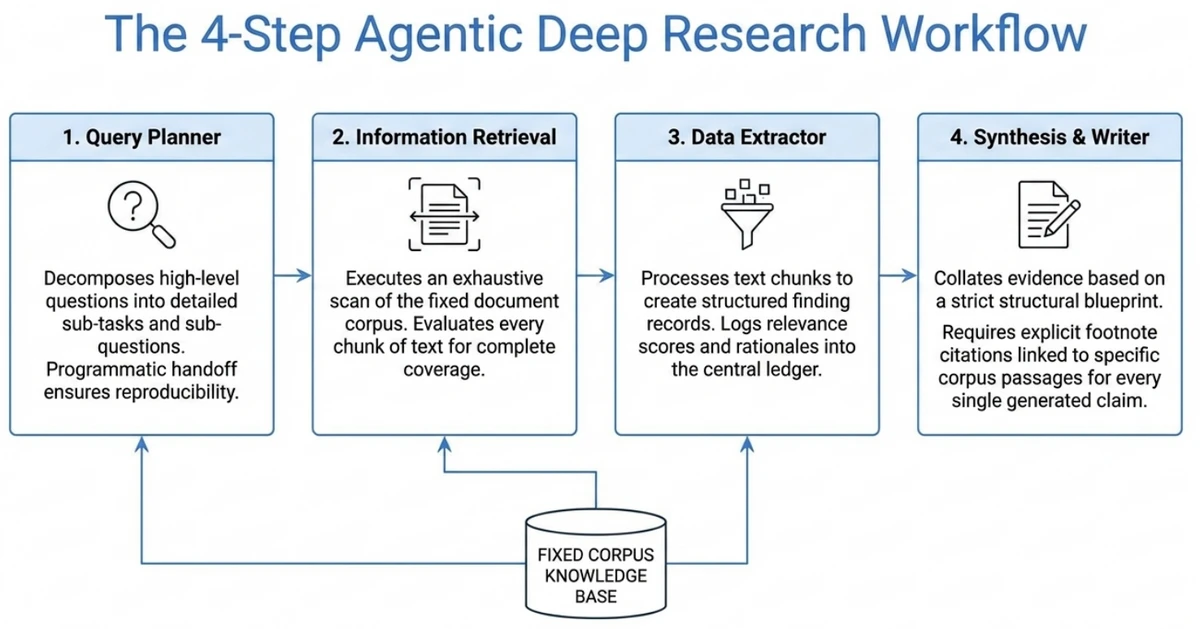
The LM-Judges: Automated Measurement Probes
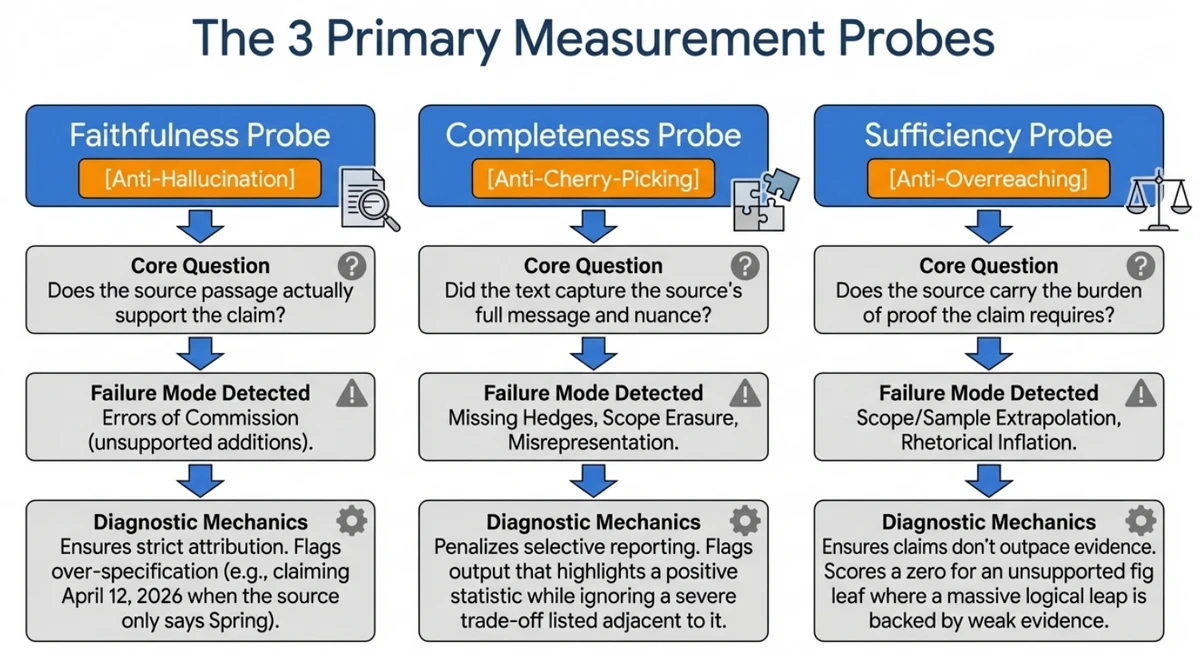
A key element of the ITL project is the introduction of “LM-Judges” or measurement probes. These are narrowly scoped agents (using LLMs) designed to act as adversarial verifiers. The harness runs the LM-Judges against the Writer Agent’s, stress-testing each claim against the evidence.
The system deploys three primary probes that evaluate every citation exhaustively and rate text segments with scores (ranging from 0 to 1):
Traceability and Autonomous Self-Correction
The scores from the LM-Judges, along with detailed text rationales, are compiled into a JSON audit trail. This ledger records the chain of reasoning, tool usage, and the precise evidence behind every decision.
For federal agencies, this traceability is mandatory. In order to meet NIST SP 800–53 security controls, security controls must pass rigorous annual audits. A machine-readable ledger provides auditors with empirical evidence of data integrity and AI decision-making processes.
Furthermore, this architecture enables a reviewer-style feedback loop. Because the probes trigger the moment an agent finishes drafting a specific segment, the judges provide immediate feedback. The framework notifies the agent of a low sufficiency score, so that it can recognize and rewrite the response before the final output reaches the user.
Guiding Future Federal AI Architectures
Impressively, NIST ITL released this entire project as open source. The codebase is publicly available on Github.
Federal IT teams can clone this repository today to incorporate and expand upon these measurement concepts. By seeking empirical validation and machine-readable audit trails, we can elevate AI from a black-box novelty into a governable, reliable digital co-worker.