
By Dr. Robert Buccigrossi, TCG CTO
 ChatGPT is amazing, but it hasn’t revolutionized the world as we might have first imagined. Why? Because it has significant limitations. However, there are exciting frameworks recently developed by AI researchers that give large language models new capabilities such as planning and long-term memory. In this article we’ll explore the limitations of modern large language models, describe the new tools that push the boundaries of generative AI technology, and predict what future advancements will look like.
ChatGPT is amazing, but it hasn’t revolutionized the world as we might have first imagined. Why? Because it has significant limitations. However, there are exciting frameworks recently developed by AI researchers that give large language models new capabilities such as planning and long-term memory. In this article we’ll explore the limitations of modern large language models, describe the new tools that push the boundaries of generative AI technology, and predict what future advancements will look like.
The Limits of Modern Large Language Models - Back in March of 2023, I had fun trying to get ChatGPT 3.5 to play the text game “Adventure”. ChatGPT was able to quickly learn the rules, but it seemed to lose track of what it was trying to do. It would aimlessly bounce between areas and eventually would forget what the rules were.
Anyone who has tried to work with a large language model (LLM), such as ChatGPT, Google Gemini, or Meta’s Llama2, quickly runs into these limitations:
- Limited Memory: The history of a conversation is limited to a “context” size. This size has significantly grown (ChatGPT 3.5 had a context size of around 12 pages of text while the latest release has a context size of around 192 pages), but once information falls out of the context, it is gone.
- Losing Facts in Larger Input: While a larger context helps an LLM remember things, the LLM will lose details in a large document. This is demonstrated by the ”Needle in the Haystack” test, which shows that the ability for an LLM to recall a fact decreases as the context size gets larger.
- Problems with Multi-Step Activities: The quality of an LLM’s writing clearly decreases when asked to incorporate multiple sources of information simultaneously, or execute multiple goals simultaneously (for example, write a proposal section that identifies a customer’s problems, describe our solution, and explain our solution’s benefits to our customer).
- An Inability to Do Arithmetic: While an LLM can describe the steps to do long division, it cannot show the long-division steps to divide 49152 by 256. This is closely related to an LLM’s inability to conduct multi-step activities. (Recently, OpenAI added the ability for ChatGPT to call small Python scripts to do arithmetic, but that side-steps the lack of higher-level planning.)
- Fabrication to Fill in the Gaps: LLMs will generate plausible-looking but false details when facts are not readily available in its context. LLMs are trained to mimic the structure and content of human writing, conversation, and code. While their neural networks have absorbed and can repeat massive amounts of scientific, historical, and cultural facts, they do not differentiate between truth and false statements. (Intuitively, an LLM relates words and concepts that frequently occur together in its training set without regard to “truth”.) When asked, an LLM will effortlessly make up addresses, books, URLs, people, places, events, and stories out of thin air to fit the pattern of conversation.
Yet LLMs have one key ability: It can truthfully and accurately answer many college and graduate level examination questions, including text comprehension, short essay, and subject matter multiple-choice questions. ChatGPT‑4 scored 710/800 (93 percentile) in the SAT Evidence-Based Reading & Writing reading and 700/800 (89 percentile) in SAT Math, as well as scoring well in the GREs, LSATs, and even the Uniform BAR Exam.
Its ability to perform well in standardized tests underlines a very important property of LLMs: A high-quality LLM will accurately answer simple analysis, comprehension, summarization, and writing prompts when presented with facts and trustworthy material. In addition, some LLMs, such as ChatGPT‑4, have the ability to write simple blocks of code, including Python, SQL (for databases), and Mermaid.js (for diagrams).
As a result, our ability to solve a problem using LLMs (such as reviewing a form for errors, drafting a proposal section, writing a unit test, or identifying infiltration attempts in web logs) depends upon our ability to break the problem down into simple SAT-like questions and simple coding problems and pass information to the LLM as it needs it.
Amazing Progress In Frameworks that Expand LLMs Abilities — Over the past year, researchers and AI enthusiasts have developed frameworks that solve problems that LLMs cannot solve by themselves.
RAG — Providing Trustworthy Information to LLMs: An approach that is the basis for many new open source and commercial products is “Retrieval Augmented Generation” (RAG). The goal of RAG is to provide trustworthy information and reference material to the LLM without the need to retrain the model’s neural network. The following is the architecture of a RAG system:
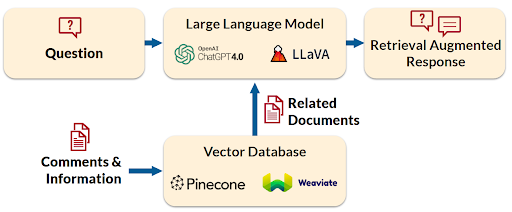
First we populate a special database (called a “vector database”) with trusted source information needed for a task, such as past proposals (for a proposal writing system), journal articles (for a research assistant program), or API details (for a code writing assistant). What’s special about a vector database is that it can quickly retrieve text based upon related keywords and phrases. Then, given a prompt (a question or request), a RAG system will pull out related material from the database and include it to the LLM with the prompt. This essentially turns the prompt into an SAT-like language comprehension problem. As a result, the LLM has the information it needs to give a truthful answer with verified sources.
An effective example of using RAG to quickly teach an LLM new information is the open source project Vanna. Vanna converts plain language questions into SQL queries. Let’s say you had a database that you wanted to query with plain text prompts (e.g. “How much did we spend on computers in 2023?”). To use Vanna, you would give it the schema and documentation (like plain text definitions of tables and fields), and Vanna would store this information into a vector database. Then, when given a text prompt, Vanna will search for related schema definitions and use that to ask an LLM to create SQL from the prompt. Because LLMs are pretty good at developing SQL, it is able to create appropriate simple queries.

Cooperative Agents to Break Down Tasks and Verify Results: In July of 2023, Brown University and multiple Chinese researchers collaborated to develop ChatDev, an environment for “Communicative Agents for Software Development”. ChatDev is an LLM framework that takes a prompt describing a small piece of software (e.g. “write a pong clone”) and coordinates the actions of multiple agents taking on different roles:
- Chief Executive Officer (CEO), Chief Product Officer (CPO), and Chief Technology Officer (CTO) — to break down the project into sequential atomic tasks
- CTO, Programmer, and Designer — to develop code
- Programmer, Reviewer, and Tester — to test code
- CTO, Programmer, CEO, and CPO — to document code
Out of 70 tasks (randomly chosen from a collection of 2500 tasks), it succeeded in developing 86.7% of the software tasks, with half failing due to the context limit of the LLM, and half failing due to Python library resolution errors. A key element of its success is the use of adversarial (“instructor”) roles and “inception prompting” to have one agent critique and guide the work of another agent, reducing hallucinations and keeping work on track.
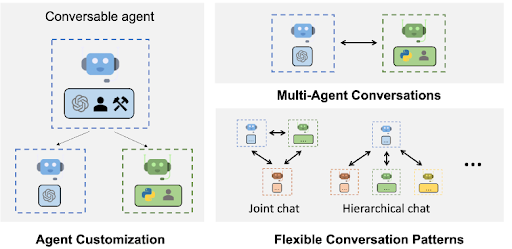
Cooperative Agents Any Developer Can Use: To promote “next-gen LLM applications via multi-agent conversation”, in September 2023, Microsoft released AutoGen, a Python framework that allows any developer to quickly create multiple collaborative LLM agents, including pre-made roles for group chat coordination, user interaction, and Python development.
Exciting Advancements - Over the next couple of months and years, I believe we will see exciting advancements because of new LLM frameworks that creatively use cooperative agents and memory models. Such frameworks will dramatically out-perform large language models running by themselves.
Using Vector Databases to Learn from Past Experiences — LLM frameworks will be able to quickly gain experience, which is not possible with a static large language model. If roles (in a cooperative agent framework) were given the ability to write to vector databases, then we could have “planning” roles that not only break down prompts into a series of tasks, but can “remember” task breakdowns that work and those that fail. Similarly, “developer” roles could record errors they encounter, how to fix them, and avoid those errors in the future.
Adapting to Changing Environments — Once LLM frameworks can learn from past experience, they will need to outgrow simple vector databases in order to handle environments that change over time. We will need to allow our long-term memory models to give more weight to recently used successful memories. In this way long-running LLM frameworks will not get stuck in the past, will learn new lessons, and adapt to change.
Resilient Executive Workflow - ChatDev, Vanna, and LLM Frameworks developed with AutoGen have workflows that determine what agent roles get involved at what time, the flow of data, and the prompts that are used. The more that roles are used for planning (such as ChatDev’s CTO role) and error correction (ChatDev’s tester and reviewer role), the more autonomous and flexible the LLM framework is. I believe that ambitious cooperative LLM Frameworks will result in surprisingly self-reliant, resilient, and adaptive systems.
Oversight, Ethics, and Safety - Finally, LLM frameworks with cooperative agents will provide a natural way for us to introduce oversight, ethics, and safety into our AI systems. Workflows will be able to include steps and agent roles that will: 1) predict the impacts of an activity, 2) verify that an activity and its impact matches a code of ethics, and 3) verify that an external observer would trust the results of an activity. While LLMs do not “understand” right and wrong, they criticize work and answer questions about ethics pretty well, allowing adversarial roles to potentially be an effective first step in detecting unethical or dangerous behavior.
Democratizing AI Advancements - We are at a point where advancements in AI are no longer the sole domain of the multi-billion dollar companies. Any software developer has the ability to grab AutoGen and a vector database to experiment with the cutting edge of AI capabilities. In just the first two weeks of March 2024, Hacker News had three announcements of LLM frameworks that drew significant attention:
- Devin (HN announcement) — the “first AI software engineer” announced by Cognition labs. This commercial product appears to be a concept similar to ChatDev but has an IDE that allows users to observe software development.
- Skyvern (HN announcement) — Open source “browser automation using LLMs and computer Vision”. By giving Skyvern a goal and input data, it will access your browser, use multi-modal LLMs to parse forms on your screen, and attempt to accomplish the goal by interacting with your browser.
- LaVague (HN announcement) — Open source conversion of natural language commands into Selenium code to interact with a browser. One of the project’s todo items is to “memoize” successful commands in a database to improve future browser interactions.
We are at a unique moment in history where participating in AI advancement is available to any developer who wishes to take the reins. I am excited to see that significant work in LLM frameworks is done out in the open, where we as a community can help each other strive for successful, shared, trustworthy, and ethical solutions.