
 By Robert Buccigrossi, TCG CTO
By Robert Buccigrossi, TCG CTO
Machine learning (ML) is all over the news. It can beat humans at Go, but has caused a backlash grading Utah students’ essays. So what problems can we effectively solve by an ML system right now? Here are a few examples of how ML can be used to improve existing government technology.
Classification (tagging & decision making) – In this type of problem, we are given text or data, and we want to tag or categorize the information. Examples include:
- Spam detection – Here we try to determine if an email or post is legitimate or unsolicited junk. NITRC.org has a simple pattern-matching system that scans any submitted data for key phrases and rejects a post if it is determined to be junk. If the pattern-matching system is replaced with machine learning, as spammers invent and release new spam, users could report it and the ML system would automatically learn.
- Post tagging – Given text (like an article or trouble ticket) can we suggest tags to identify key topics? The Office of Government Ethics site uses tags to help users search and find articles of interest. However, there are years of legacy articles that are missing tags. ML can be used to help OGE quickly catch up with their article tagging.
- Submission compliance – Does a text or data submission comply with a requirement? GSA’s Solicitation Review Tool (SRT) uses ML to review beta.sam.gov (formerly known as FedBizOps) postings to determine if they have rules for accessibility (Section 508). It uses the “word vector” approach that I describe in my “Shakespeare or Melville” ML article. However, instead of deciding if a passage of text is more like Shakespeare or Melville, it determines if it has Section 508 requirements or not.
- Decision making – Does text or data submission meet the requirements for approval? Since “yes” and “no” are decision categories, ML can be used to look at past decisions and predict if we should approve a submission. Should we pursue a project? Should this grant be approved? As noted below, there are some key practices we must use to have confidence in the ML model.
Predicting numerical values – In this problem, we want to predict a number (or set of numbers) given input text or data. Examples include:
- Web traffic predictions – Can we predict how many users will hit the site given the next submission deadline, day of the week, and number of registered users?
- Financial data – What is our predicted earnings next year given our sales pipeline, current agreements, number of employees, etc?
- Probability of user activity – What is the chance that a user will click on a particular link? Given this prediction, we may pre-load data to dramatically improve user experience.
- Image zooming – If you want to make an image 4 times its original size, ML can be used to predict the detail in the missing pixels without having the result look “fuzzy”. You’ll also find similar approaches for erasing items in images that you don’t want there.
What helps the success of an ML model?
- Existing labeled data – We need to have a good body of existing data that has known answers. SRT has about 85% accuracy with a training set of 900 documents. More data would help get more accurate results.
- Using a labeled test set – There is a big danger in “overfitting” a model. An overfit model is so complex that it gets almost 100% of the training set right, but then is useless for data outside of the training set. For example, the red curve line in the graph below hits all of the training data, but is horrible if we wanted a simple prediction (the black line):
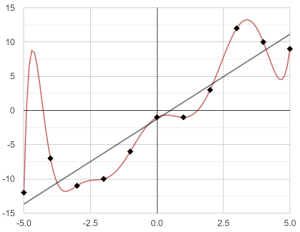
To avoid overfitting, we set aside a test set of labeled data (usually 20%), that we use to test the success of a model. (This is how we know that the SRT model is about 85% accurate.)
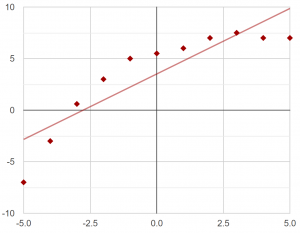
- Good features – This is a very important and challenging aspect of machine learning. While machine learning analyzes data to find correlations between the data and the answers, the more it needs to twist and manipulate the data to find strong correlations, the less successful it will be. A very simple example is trying to fit a parabola to data. If you feed “X” and “Y” as features to a standard linear predictor, you will end up fitting a straight line to the data:
- but if you also provide “X^2” as a feature, you will then be able to fit a parabola:
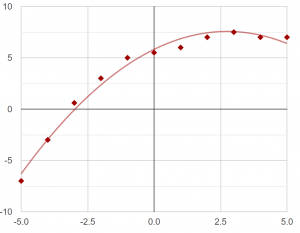
- If we find better features for ML, we will get better results.
- Using model confidence – In addition to an answer, many ML algorithms will also give you the probability that the answer is right. We can use this by designing systems that pass this information to users as a confidence level. For cases that the model doesn’t have a strong prediction, we can ask a human to help out (and then train the model with the new data).
- Looking at the used features – Many ML algorithms can let you know what features are used in a particular decision. This avoids the “black box” issue that occurred in Utah schools. By looking at the features that contributed to an answer we can identify unintentional bias and gain confidence in the algorithm’s decisions.
So, do you have a problem that ML could help solve?
For more on machine learning and emerging technology explored by TCG’s R&D lab, follow Robert Buccigrossi on LinkedIn.